What I’ve been doing lately¶
Lately my work has been mainly driven by the need to efficiently and smoothly deploy the Accounting module of OpenERP in my employer enterprise. But at the same time I’m responsible of several development and deployments in the enterprise.
The accounting-related tasks have made me to study the accounting module, but also accounting in general from fundamental principles to advanced topics. I currently own a collection of 9 books about accounting. I still have more studying to do, but now I’m versed enough to the point of being a (very junior) accounting consultant to the CEO. This, of course, should yield future benefits since I’m planning to start a business.
On the technical side, the last week I was doing a final verification of the module so that the (true) accountant of the enterprise finally migrates to OpenERP: Taking our QuickBooks files and, with Pentaho Kettle, migrating the accounting information to OpenERP, and comparing the legal reports. This has finally yielded good results and we’re doing an opening entry to continue accounting in OpenERP (the enterprise has an accounting period the starts on Oct, 1st each year).
At the same time a new server for OpenERP and a deployment based on Buildout was another one of my tasks. There’s still much to be done and I’m wondering if Ansible would be a good choice to actually manage the deployment since it involve setting up Postfix as the Mail Transfer Agent interfacing OpenERP for emails. This means that besides the accounting books I have reviewed several email related RFCs (2822, 2821 and 2476 being those I’ve read the most) and the Postfix documentation.
To fill the gaps, or more precisely: to take breaks from these topics I’m reading a couple of books and articles:
- High Performance Browser Networking by Ilya Grigorik.
- Distributed Systems
- The report about Convergent and Commutative Replicated Data Types of Marc Shapiro and others. RR-7506, pp. 50 <inria-00555588>.
- And for fun, the last book of the Rama saga of Arthur Clark and Gentry Lee. Which BTW I’ve only truly enjoyed the first book.
Things left in the attic¶
At the beginning of 2014 I expected I could dedicate myself to finish xotl.ql by August. This was, however, not possible. I still keep my eye on the topic from time to time, but this needs a lot of time to actually make a breakthrough.
Apples and Oranges. How books can mislead our thinking process.¶
I’ve just began to read the book “Twisted Network Programming”… Twisted is a popular framework for networking programming. However, I’d probably skim most of the Book. I’m sorry… But as it happens, in the second page of the second chapter (the one that I began with) they show an illustration on “Comparing single-threaded, multithreaded, and event-driven program flow”.
Hum… apples and oranges. I mean the thread model of a program will have some impact on how events are dealt with, but are they truly comparable or the sole responsibles for the program flow?
Diesel is usually ran in a single thread and so is Tornado. You may, of course, run programs written with them in multiple processes (or threads) to avoid contention when the volume of clients (events) is too high.
Even with a single thread most of the time the system is waiting for the IO buffers to have data, so they can be classified as event-driven: They actually response to events.
But what really bothers about this illustration is not that it compare two thing that could be (and should be made) complementary. What bothers me is that the picture tries to fool me by showing that event-driven programs don’t have any “gaps” of idle time between tasks, while the threaded models do. And that’s simply dishonest.
Probably this is not what the authors meant, and I’m probably going prejudiced just because of this wrong picture. However, I go to a book like this not for pleasure but for information. Finding a piece of data that is not trustworthy raises a flag and I start to read with a magnifying glass… And that’s not fun either.
Don’t expect me to finish this book.
Update of a couple of hours later…
A few lines below the illustration of matters, they actually say:
“The event-driven version of the program interleaves the execution of the three tasks, but in a single thread of control.”
So, let’s give it another try.
Reviewing Odoo 8.0¶
This is the first of a series of blog posts related to the next OpenERP 8.0 (or should I say Odoo 8.0). This first post will be very “seeking for orientation” on major new features and changes. Don’t expect anything to be deeply commented or analyzed.
I will probably devote several posts for changes in some modules, but in this one I’ll just write about things that can be immediately seen when you first install it.
Installing Odoo 8.0¶
I’m working with a clone from the now official github.com odoo repository. Of course I’m using the branch “8.0” for this review.
I prepared a virtual environment and installed odoo there like this:
$ python setup.py develop
The first I noticed is that several new requirements are in place, and the pyPdf requirement had been forgotten.
Second thing noticed is that unlike the “7.0” you don’t need to run the openerp-server script passing the --addons-path=./addons. In 8.0 they include this path automatically. So running ./openerp-server is enough.
Also the python setup.py sdist command includes this path as well, so a properly built distribution from source seems more doable. I haven’t tried this yet, but I will, cause that was for sure something missing in 7.0. It’s quite suspicious that the tarball is too small (around 13MB) though.
New addons¶
Instant Messaging¶
Once I ran the server I installed a demo DB to see what’s new. The first thing that captured my attention was an “Instant Messaging” module. I gave it a try and it seemed to work out-of-box.
It uses the quite old long polling technique instead of the brand new HTML5 Server-Sent Events (SSE) stuff. Why?
My first guess was that multi-process deployments would need to pass messages around between the HTTP processes. That requires a kind of Inter-Processes Communication (IPC). Popular choices for achieving this in web applications are Redis and RabbitMQ, but then you’d need to setup either for this to work.
After thinking in this a bit more (actually the thinking about this occurred at the same time I was writing this post) I realized that the current multi-process deployments would still need this IPC to properly work. So I ran ./openerp-server --workers=2 and tested it again. The chat stopped to work and the following error was logged from time to time:
2014-08-27 22:53:48,972 17858 ERROR o8 openerp.http: Exception during JSON request handling.
Traceback (most recent call last):
File "/<..>/odoo/openerp/http.py", line 476, in _handle_exception
return super(JsonRequest, self)._handle_exception(exception)
File "/<..>/odoo/openerp/http.py", line 495, in dispatch
result = self._call_function(**self.params)
File "/<..>/odoo/openerp/http.py", line 311, in _call_function
return checked_call(self.db, *args, **kwargs)
File "/<..>/odoo/openerp/service/model.py", line 113, in wrapper
return f(dbname, *args, **kwargs)
File "/<..>/odoo/openerp/http.py", line 308, in checked_call
return self.endpoint(*a, **kw)
File "/<..>/odoo/openerp/http.py", line 685, in __call__
return self.method(*args, **kw)
File "/<..>/odoo/openerp/http.py", line 360, in response_wrap
response = f(*args, **kw)
File "/<..>/odoo/addons/bus/bus.py", line 188, in poll
raise Exception("bus.Bus unavailable")
Exception: bus.Bus unavailable
The code explains it all. This is the method ImDispatch.start() in file addons/bus/bus.py:
def start(self):
if openerp.evented:
# gevent mode
import gevent
self.Event = gevent.event.Event
gevent.spawn(self.run)
elif openerp.multi_process:
# disabled in prefork mode
return
else:
# threaded mode
self.Event = threading.Event
t = threading.Thread(name="%s.Bus" % __name__, target=self.run)
t.daemon = True
t.start()
return self
The highlighted line says this won’t work in a multi-process deployment. How do you get to use the evented mode, I don’t know. Probably that’s the default now.
So I need to review this feature more closely before going to production. It’s a nice addition though.
I found they have now a GeventServer for long polling connections. And the implementation of the Instant Messaging Bus (bus.py) can be easily adapted for desktop-like notifications, updating your message inbox, and many other features that would benefit from this.
Messaging has gone a bit different¶
At this point I tried to send a message from a user to another (to test if the inbox was updated real-time) and realized that the Messaging addons has lost the “compose a new message” that was previously accessible from the inbox, let me show you a picture (7.0 on the right, 8.0 on the left):
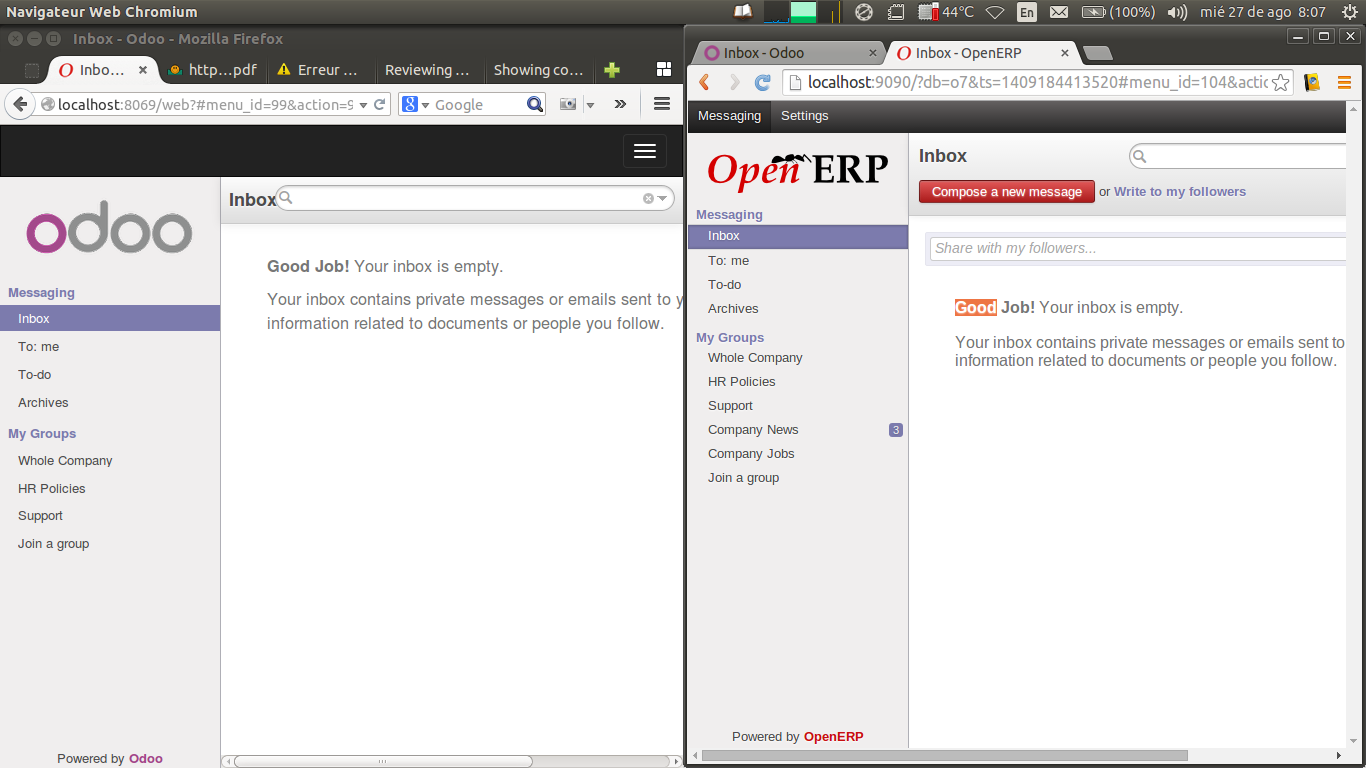
Odoo is missing the “Compose new message” button.
This commit has some explanation:
commit 0714b231646bb439b121a6aaa43df32fedcb5e6e
Author: Thibault Delavallée <tde@openerp.com>
Date: Wed Aug 13 14:35:25 2014 +0200
[FIX] mail: when having only mail installed, do not show any 'share with my
followers' compose box. This comes only with hr, for the inbox. This was
probably forgotten when updating the mailboxes hr-goal and hr-related
gamification / chatter stuff.
I then installed the “Employee directory” addon and the “Share with my followers” box appeared.
More digging in the logs reveals the following:
commit e6f8666b521fe8c2522d6e94c0c3def54a5f73ed
Merge: d57a97d bf3d4a7
Author: Amit Vora <avo@tinyerp.com>
Date: Thu Apr 17 11:41:33 2014 +0200
[MERGE] [IMP] mail: Inbox usability improvements :
- notficiation_email_send field, renamed into notify_email, has now 2 values: always or never, in
order to ease the choice and simplify options.
- inbox: removed 'compose a new messages or write to my followers', because those 2 options are
already available. The first one is accessible using the top-right email icon, the second one
is accessible with the 'write to my followers' text box alread present in the inbox.
However I don’t see the mentioned “top-right email icon”. In fact, that icon is present in 7.0, but not in 8.0. More digging:
commit 5209fbc7ed9fcad966ab064654a8a8697142be42
Author: Antony Lesuisse <al@openerp.com>
Date: Mon Jun 30 01:51:40 2014 +0200
[REM] useless icon send a message
The action is available from the wall.
Got you! So, Antony removed the icon cause he thought it was the wall, but Amit had removed it from the wall cause because of the icon. These things happen…
After reverting this commit, the icon is reestablished. But, then I realized that the feature, however hidden, is actually there: If you click on the “Share with …” and instead of writing your message there, click on the “expand” icon, then you get the same as pressing the (now missing) email icon. I think that the icon is required, though, since now the “Share…” box is not shown until HR is installed, and the email icon allows to send email to outsiders. My current employer is willing to remove email in favor of this messaging module. This may hold him back.
I’m raising my hand to vote for the rescue of (at least) the icon. Redundancy is not always bad when it comes to user interface.
This enough for this post. I’ll keep looking at Odoo and I’ll write about it.
Integration v. Automation¶
Being an OpenERP bee these days has lead me to think a bit about integration, how does it happens inside OpenERP, its architecture, assumptions and other stuff. In a first iteration I used to think about integration in terms of integrating two (or more) OpenERP addons, for instance, integrating Sales with Accounting. At a very programming-oriented level this reduces, in the current state of OpenERP, to integrate their modules. But later, I found out that this approach is fundamentally flawed and causes many quirks.
This post starts with a tale about one of the many issues we have encounter when deploying OpenERP in an small enterprise. Then I will argue about what integration means. Lastly, I will turn to automation as a mean for integration and not the only way to do it.
The Integration tale¶
I want to start with a simple and very real [1] use case: Bob is a salesperson processing a CRM lead.
The story beings when Bob opens the lead and clicks on the Edit button and the first thing he tries to do is to fill the client’s contact info because it’s a new client. He clicks on the edit button besides the “Client” field which opens a window. He fills the data and clicks “save”, but suddenly it fails saying that Bob (a salesperson) should have filled the “Account payable” and “Account receivable” fields. So Bob says:
Oh, boy! What did I do wrong?. Let’s try again… Nope… Uh. What should I do?
Hey! Peter. Do you know what’s happening here? This won’t let me enter this client’s contact data, it keeps telling me that these accounts are wrong? What the heck are these accounts anyway?
And Peter has no idea, so he calls Sally who’s a very pretty girl that probably does not have a clue either about what’s happening but it’s so nice to have a reason to approach her… Surprisingly Sally seems to be only one who actually paid attention to the information meeting that morning and she says:
Ah! This probably has to do with the Accounting module being installed. They say they will do that today… Let’s ask Stephanie.
And Stephanie realizes what’s happening and fix it somehow. An hour later Bob can resume his work and finish processing his CRM lead.
The end.
So, what is wrong with this story?

Computer Problems. Taken from xkcb.
Depiction of wrongness¶
In my opinion there are two things that are clearly wrong with this:
Requiring data when it’s not required. When you’re in a CRM use case requiring accounting-related seems really overstepping.
Not being able to issue a request for completion. Bob should have been able to keep working and after the new client was saved a completion request should have been sent to those being able to complete the data.
That completion request might just get ignored, but other use cases (like submit an invoice to that client) would actually require the data and thus the cycle would be closed after all.
Some would think that this is just a “configuration problem” as we will discuss below. But finding that solution took me several dives into the code and re-parsing of the documentation, so I’ll try to walk you through the process.
The issue. The making off¶
Warning
Technical stuff ahead. Wearing hardhats is mandatory.
By installing the “Accounting & Finance” addon [2] you touch many parts of your system besides installing new stuff. In fact, the module forces the installation of many other modules, including product [3].
It also modifies the "res.partner" model from the base addon. You may think about the "res.partner" model as an attempt to merge the contact information for both clients, suppliers and employees into a single entity [4]. It has many fields that comprise name, job position, contact information, etc…
When you install the account addon, the "res.partner" gets appended a whole bunch of other fields, including the said “account payable” and “account receivable” fields, which are also marked as mandatory:
'property_account_payable': fields.property(
'account.account',
type='many2one',
relation='account.account',
string="Account Payable",
view_load=True,
domain="[('type', '=', 'payable')]",
help="This account will be used instead of the default one as the payable account for the current partner",
required=True),
'property_account_receivable': fields.property(
'account.account',
type='many2one',
relation='account.account',
string="Account Receivable",
view_load=True,
domain="[('type', '=', 'receivable')]",
help="This account will be used instead of the default one as the receivable account for the current partner",
required=True),
This are not actual fields of the model "res.partner", but properties, which are “special”.
On using properties¶
Properties are of course related to the “solution” for the problem described above. But the solution is well hidden under the title of Database setup in the OpenERP Book. That’s the reason I’m using this case to open the OpenERP corner. If you deploy CRM before accounting [1] you’d probably find no interest in reading a topic called “Database setup”… you have set your database up already, haven’t you?
You should notice that both Account receivable and Account payable are, in fact, properties (i.e defined via fields.property). This actually means that those fields take their default values from a global configuration.
Those values were not properly set in our case cause there were no localized account chart that applied to our enterprise. We have to create all the accounts by hand, and yes, we missed (didn’t know) that we have to create those properties.
Our problem is solved by defining those properties in the configuration menu.
However this workaround is very unsatisfying:
- It involves the administrator of the system because he’s the one that has access to the “Configuration Parameters”. AFAIK, the accountant himself/herself cannot change the defaults, unless you bestow all the powers on him/her.
- It does not resolve the integration problem others might present in the future. Integration is harder that having some default values. For instance, Cuban accounting norms establish more than 10 accounts for receivables with empty slots for more if needed. They require to have different accounts (receivable and/or payable) for bills to/from people (B2C) separated from those bills to/from other enterprises (B2B), and also different accounts for long-term and short-terms bills. The last case cannot be decided by just looking at the client or supplier, more information about the economic fact is needed.
- It does not actually resolve the current integration problem since the accountant needs to make sure the “Account Receivable” is the correct one for the client and he’s not notified when salesman Bob creates a new partner. So, what really happens is that the accountant needs to review journal entries and before posting them, and change the account if needed.
Integration v. Automation¶
An ERP should simplify things by integrating business areas, shouldn’t it? That’s the main driver behind the feature of automatically generating journal entries. Under this principle when an invoice is sent to a client a journal entry should be made recording we should get paid for that, ie. the client’s account receivable gets increased [5]. Likewise when we get a supplier invoice, an entry should record that we must pay that bill, ie. the supplier’s account payable gets increased.
You see now how the “Account Receivable” and “Account Payable” fields for the partner play their part in the automation of the accounting processes. This is deeply weaved into the account module’s source code. Meaning that there’s the assumption that partners have those properties we’re talking about. And that’s true because you have injected them and, if you configured everything as expected, they have their default values.
Notice the difference between the expectation of integration of business areas and how the integration happens in this case via a very specific kind of automation.
I’ll argue that the current state of this design is flawed. When standards change and/or are not applicable this kind of automation does more harm that it helps.
This is the reason the module that controls the “Anglo-Saxon accounting” [6] is very difficult to understand and the result artificial: they need an “interim” account to keep track the different stages. In the standard (for OpenERP) accounting the event to produce journal items in the debtor/creditor account is the creation of the invoice. In the anglo-saxon scheme the journal should be created at shipping time.
I argue that given another framework that clearly separates every actor and function will improve how this pattern could be implemented. I think that this framework must have:
- Signals and events.
- Actors like the accountant, and probably an automated agent for the accountant that could do the same the models do right now. But being responsive (ie. they respond to signals) they could be easily bypassed.
Of course there are more things needed. I’m thinking about those two plus the ones OpenERP already has.
I think that recognizing actors is the major improvement. Actors are abstractions about intelligence. If a person should be doing some kind of intelligent decision (like accountants), then you should encode (in your design) that decision as being taken by an actor.
Having artificial agents that could take over when the task is standard or programmable is also an option in this case. Anywhere in you design an actor does something, and agent could be replacing the human. The agents could be as dumb as the couple of rules we have now: create a journal entry each time an invoice goes to the valid state, and do it this way. But agents could be also provided of machine learning techniques and they could observe the how the human accountant proceeds when something happened. Of course this would require the human to proceed in case-by-case fashion and that’s not always true.
No matter if the machine learning is never done, I argue that designing with actors and agents will lead to better a implementation, easier to understand, maintain and evolve.
Notes¶
| [1] | (1, 2) This is no hypothetical at all. We’re actually deploying Accounting after having deployed Project Management and CRM. This has come with many surprises but that’s what this post is about. |
| [2] | The word addon in here is important. There are actually two OpenERP addons named “Accounting & Finance”: the account addon and the account_accountant. The second one is flagged as an application and, thus, it takes a more prominent place in the listing of available applications. Installing the application forces the installation of the account module anyway. |
| [3] | That is why I still do my personal (home) accounting with GNU Cash. |
| [4] | This merge has problems of its own, but that’s a matter for another post. |
| [5] | Though an account either gets credited or debited, I will avoid that accounting-related terms cause it’s not needed for the argument in this post. If you need to know, start by knowing that receivables have a debit normal balance and go from there. |
| [6] | I’m not quite sure if this “anglo-saxon accounting” refers to different basis of accounting. |
Odoo… I mean OpenERP¶
This is old news: OpenERP has changed its name and now becomes Odoo. I don’t care much about the change in the name. It’s the processes I’m interested in.
The rename was synchronized with a move from Launchpad to Github. This, I much appreciate it. I’m one of those that once the Git virus got me, I’m almost unable to work comfortably with any other Version Control tool.
I this regard I have a couple of questions:
Will they use the “standard” Github’s pull-requests model for contributions? Probably they are longing for this kind of long-tail of contributors model to kick off now at Github. I haven’t found any “Why the move to Github” in the FAQ of the move and other sources (but again my connection is slow and I didn’t waste much time).
Will they require some kind of a “waive” of copyrights to accept contributions?
The model of the Plone Foundation requires this. But this foundation is non-profit unlike Odoo.
Does this align with the company’s view of the Open Source model? I don’t know.
So, my only strategy is:
- Fork the Github repository
- Send as many PRs as I’m able to fix/improve something and hope for the best.
Postdata¶
My long-planned “OpenERP corner” will simply be renamed accordingly.
This reminds me I have broken my promise to keep my old blog in-sync with this new one. Apologies. But it’s sooo comfortable to work with this blog-model that I barely looked back once. So I’ll announce it: I will not keep my old blog anymore. I will commit myself to improve the look of this one and that’s it.
TDD is dead rally¶
These days there’s a kind of a rally about “TDD being dead”.
Most TDD fan supporters are true that you must have a way to proof your code works. Many computer scientists have done several attempts into the “proofs of correctness” for a program. But tests are not always proofs, some are [1].
I think the main argument is about when TDD is too much. Several Destroy all software screencasts show a TDD flow that I simply find it’s too much. But they are, indeed, screencasts; and they are probably intended to illustrate a point and not to be followed without deviations.
Nevertheless, I don’t like the “TDD is dead” mantra either. It gives space to a flame war I’m not willing to get into. I use tests and that’s it. Tests, at different, levels may express several concerns I need to keep stable:
A public API, for instance, should not change just like that. At least not after you have made the commitment to keep it stable.
You may even need to test for deprecation warnings being issued when you need to change an API.
Collaborative in-progress debugging. This tests allow to express standing issues. Some regression tests fall into this category.
How do you do tests?
Update: Amplification and support to David’s arguments¶
The previous words were written just after skimming over several tweets. I had read David’s test-induced design damage but I had missed the previous post TDD is dead. Long live testing. So this update is my one cent to the issue, but I will not discuss about “slow collaborators” but about my design experience with our Python Query Language.
The test-first mantra assumes too much about how you are going to decompose your problem. Let’s start with a retrospective account of how this happened in xotl.ql.
I can detect four distinct stages:
The beginnings. Slightly TDD, but the tests were not always written before code. Since xotl.ql is just a language we were not sure about what to test.
The idea of having a query object that stands for the expression was not totally consolidated. The components of the query were not defined. This stage was heavily driven by our own writings, like this one.
In this case the “literate” spirit dominated the design process, not the testing. Simply we didn’t have a full-stack: ie. the language and the translators so that a query could actually be executed.
Consolidation of the design. In this stage several devices were invented to cope with implementation difficulties, i.e. the lack of clear boundaries between several sub-expressions in a single query.
This was the hardest stage. Testing was employed to keep track of several design decisions. In this stage made appearance our “Particle Bubble” and this was complex enough to deserve a handful of tests. Although several tests did influence the design, they hardly drove it.
Then the core was done and we turned to translation. This stage was mainly TDD cause we actually were testing a very TDD friendly layer: Given this state of the world, the following query should return these objects.
Our current stage. Although in a long pause, we have decided to wipe out our entire design and do reverse engineering of python byte-code to extract build the query object.
What is foreseeable is that again a kind of literate driven design is going to be king: The core structure of the language (the query AST) is what’s being designed so, what’s the point of asking if the result of calling a function with a given query expression is a particular AST if the AST is what’s needs to be validated not the function itself? At this point this is non-sense. At a later stage where the AST is stable enough those kind of tests would actually make sense: they will protect the query language against unintentional API-breaking changes.
Footnotes¶
| [1] | If I recall correctly, the book by R.L Graham, D.E. Knuth and O. Patashnik called “Concrete Mathematics” shows some proofs that allow “proof-by-instances”. |
Progress moving to github.io¶
As you may see, I have made some progress. Basically, I have partially ported my past look and feel, so that if looks like the old blog. I still a work in progress and the “responsive” stuff is not entirely done.
Nevertheless, I think this is good to go and will start blogging here from now on.
Enjoy!
Welcome¶
This post intends to be one to welcome my previous readers from Wordpress. I still have much to do to make this blog actually my blog:
- Polish a theme that resembles my current Wordpress look and feel. I like that central column, big fonts in big screens, unobtrusive reading and so on.
- Port my last posts to this new blog.
For the moment, though, this post is enough to avoid the default “Not found” message. For the moment, also, I’m using Tinkerer to create this blog.